


Improving the EMPIRE data assimilation code for weather forecasting and other geosciences applications
eCSE06-08Key Personnel
PI/Co-I: Peter Jan van Leeuwen and Philip Browne - University of Reading
Technical: David Scott - EPCC
Relevant documents
eCSE Technical Report: EMPIRE optimization and interfacing
Project summary
Background
Data assimilation (DA) is an essential part of any prediction system, as it generates the best starting point for a forecast based on both the numerical model and all observations available. As such it is used in all branches of the geosciences, with varying degrees of sophistication. The most advanced applications are used in weather prediction, where the system dimension is very high (currently over 109 dimensional state vectors) and very short run times are necessary (as a new 5-day forecast is required every 6 hours), so extremely efficient algorithms are needed. These codes grow over time and become complex and hard to use.
It has been discovered that the DA algorithms can be coded almost as black boxes for the different models, from weather forecasting and other geophysical applications to biology and neuroscience. This discovery motivated the development of the data assimilation software package EMPIRE, a sophisticated code focusing on geoscience applications, which encodes several state-of-the-art DA algorithms in a very efficient way. This allows researchers in all application fields to concentrate on their science without having to reinvent the wheel.
EMPIRE was developed with academic users in mind, but weather forecast centres such as the UK Met Office and the European Centre for Medium Range Weather Forecasting (ECMWF) have also shown considerable interest in it.
Project description
This project aimed to make EMPIRE more efficient in terms of random number generation and linear solves, which had been identified as the main performance bottlenecks. The first part of the project aimed to significantly speed up the random number generation, while the second part of the work was to link PETSc to the existing model infrastructure, to allow much more efficient linear solvers to be used for systems in which the matrix cannot be stored explicitly.
The typical size of the numerical models used is close to the size of models used for numerical weather forecasting, and the size of the random number vectors can be up to 109 for each time step of the model. As part of its sequential methods for DA, a huge number of stochastic perturbations were required. For example, running a 32-member ensemble of climate models required the generation of around 1 trillion normally distributed random numbers. [32*2,314,430*180*72 = 959,840,409,600]
The system previously relied on a random number generator that was downloaded from the internet without any particular consideration being given to its efficiency, as the other operations involved were substantially more costly than the random number generations. However, as a result of other algorithmic developments, optimizing the generation of random numbers is now a priority for large-scale use on ARCHER.
Vectorisation was therefore desired. A new normal random number generator using the ziggurat algorithm was optimized for performance on ARCHER. When compared with the existing normal random number generator, the new algorithm was found to achieve significant speed-up, with an 11x speedup observed with the Gnu compiler and a 2.5x speedup with the Cray compiler. This is demonstrated in figure 1.
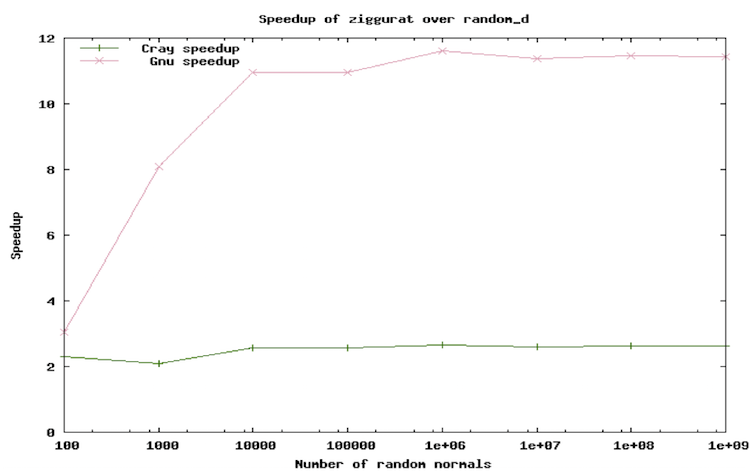
This algorithm, and hence the resulting speed-up, will be adopted by many users of ARCHER and other HPC systems in areas including meteorology, climate science, space weather, oceanography and neuroscience.
EMPIRE is designed as a general-purpose data assimilation software package. Many of these data assimilation algorithms are dependent on linear solves, and the efficiency of these can be the bottleneck in the code. Therefore, part 2 of the project investigated a usable way to interface with numerical linear algebra software such as PETSc. Linking EMPIRE to PETSc to leverage the highly optimized numerical linear algebra such as Krylov methods and algebraic multigrid methods will allow new data assimilation algorithms to be implemented. For example, EMPIRE has included within it an Ensemble Transform Kalman Filter (ETKF) which calls LAPACK to perform an SVD to do a linear solve. The more ubiquitous Ensemble Kalman Filter (EnKF) has an update step of the form:
where K = Pf HT ( HPf HT + R)-1
and hence could be implemented should an efficient method for the linear algebra be found.
The structure of this problem is pervasive in data assimilation, and hence such linear algebra could be used for implementing Kalman filters, Ensemble Kalman smoothers, optimal interpolation etc., including fully nonlinear methods, thus giving the entire user community access to new methods with the potential to improve their science.
Achievement of objectives
Success of part 1 of the project can be measured directly by looking at speed-up achieved over the existing codes for random number generation.
Success of part 2 is measured by the successful completion of linear solves using PETSc, using the existing data structures and operators available within EMPIRE. PETSc has been linked to the EMPIRE software system and used to test the linear solve (HQH^T + R)x = b. The matrix-free PETSc procedures have been adopted and will allow powerful linear solves to be used for future algorithmic developments of EMPIRE.
Summary of the Software
The work done in this project improves the EMPIRE data assimilation software system, which is part of the National Centre for Earth Observation (NCEO) national capability work, funded by the Natural Environment Research Council (NERC).
EMPIRE is a community system, maintained and developed through the NCEO as a national tool for the geosciences and beyond. Its use is growing not only within the NCEO, but also by researchers external to the organisation.
All users of the EMPIRE system on ARCHER will have access to the improvements and these will be carried through onto machines which will replace ARCHER as the UK national HPC platform in the future.
The original ziggurat algorithms are available from netlib at http://www.netlib.org/random/index.html.
The code changes have been added to the EMPIRE framework, which is downloadable from https://bitbucket.org/pbrowne/empire-data-assimilation
Documentation is available at http://www.met.reading.ac.uk/~darc/empire/doc/html