CP2K
Useful links
Licensing and Access
CP2K is freely available under the GPL. Source code can be obtained via the CP2K website.
Running
To access the executables you should load the 'cp2k' module into your environment.
module add cp2k
Serial and parallel versions of the code are installed (cp2k.sopt and cp2k.popt respectively). A mixed-mode MPI/OpenMP parallel version is also available (cp2k.psmp) and may give better performance than the MPI code on ARCHER when running very large jobs, using 2 - 4 threads per MPI process.
An example PBS script (also available in /usr/local/packages/cp2k on ARCHER):
#!/bin/bash --login #PBS -N cp2k # Select 128 nodes (maximum of 3072 cores) #PBS -l select=128 #PBS -l walltime=0:20:00 # Make sure you change this to your budget code #PBS -A budget module load cp2k # Move to directory that script was submitted from export PBS_O_WORKDIR=$(readlink -f $PBS_O_WORKDIR) cd $PBS_O_WORKDIR aprun -n 3072 cp2k.popt myinputfile.inp
Automated Submission
A helper script developed by Sanliang Ling (UCL), is provided when the CP2K module is loaded. The script takes as an argument the name of the CP2K input, and optionally the number of nodes and wall-clock time requested. It then builds and submits a PBS script. For example:
submit_cp2k myjob
submits a CP2K job to run the input myjob.inp, with the defaults of 10 ARCHER nodes and 24 hours.
submit_cp2k myjob 20
submits a CP2K job to run the input myjob.inp, using 20 ARCHER nodes and the default walltime of 24 hours.
submit_cp2k myjob 2 1 30
submits a CP2K job to run the input myjob.inp, using 2 ARCHER nodes and walltime of 1 hour and 30 minutes.
The submit_cp2k script will use the available budget with the largest amount of remaining kAUs, and will automatically select the 'long' queue for jobs of > 24 hours duration.
A log of all submitted jobs is kept in $HOME/cp2k.log
Compiling
Users can compile their own versions of CP2K, either from versions of the source downloaded from the CP2K website, or from the source files included in the package directory
Full compilation instructions are available here
Hints and Tips
- Since CP2K 2.7, CP2K will automatically search the pre-defined CP2K data directory /work/y07/y07/cp2k/VERSION/data for files. It is no longer necessary to copy standard data files (e.g. BASIS_MOLOPT, POTENTIAL) into your current working directory, just refer to them by name in the input file and CP2K will find them. It is possible to override the default search directory by exporting CP2K_DATA_DIR=/path/to/my/own/data/dir. CP2K will search the current working directory first, which is useful if you wish to modify a standard data file, just make a copy of it and edit the copy. You may also refer to files by full path.
- If your application spends a lot of time in FFTs (search for fft in the timing report), and does many SCF interations, you can improve FFT performance at the cost of a more expensive one-off planning phase by setting FFTW_PLAN_TYPE MEASURE or even PATIENT in the GLOBAL input section. Speedups of 5% are possible.
- Large, metallic systems (using DIAGONALIZATION rather than OT) may benefit from using the ELPA library. To enable this, set PREFERRED_DIAG_LIBRARY ELPA in the GLOBAL input section. Speedups of up to 5x have been reported for some systems.
Performance
A range of CP2K performance data is presented on the CP2K website. This page shows ARCHER data only, to give an idea w hat scalability can be expected from CP2K for a range of different problem sizes and levels of theory. This data can be used (if relevant) in ARCHER Technical Assessme nt forms. ARCHER users are encouraged to submit their own performance benchmark dat a for inclusion on this page - please email the ARCHER helpdesk
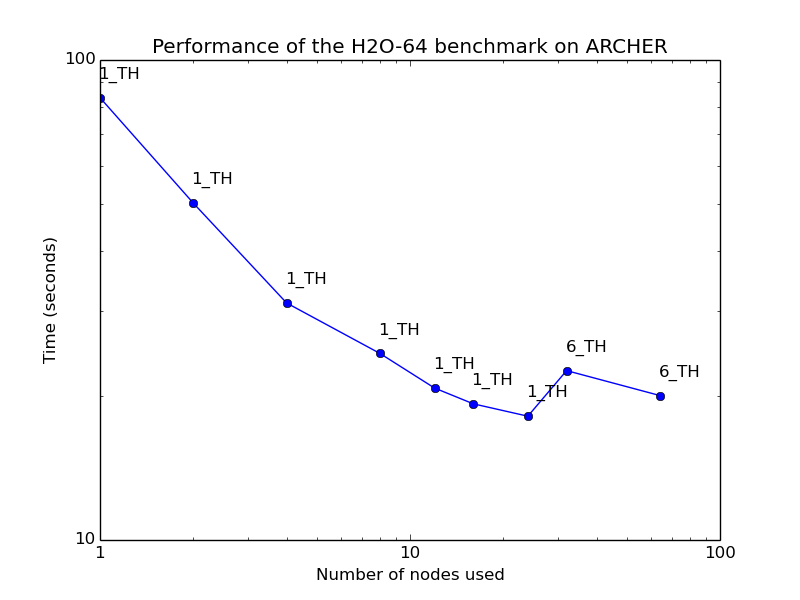
H2O-64 - local DFT
Small to medium-sized condensed phase systems using local DFT can expect to scale reasonably well up to a few electrons per MPI process (here 512 electrons). Using hybrid OpenMP/MPI does not typically improve performance.
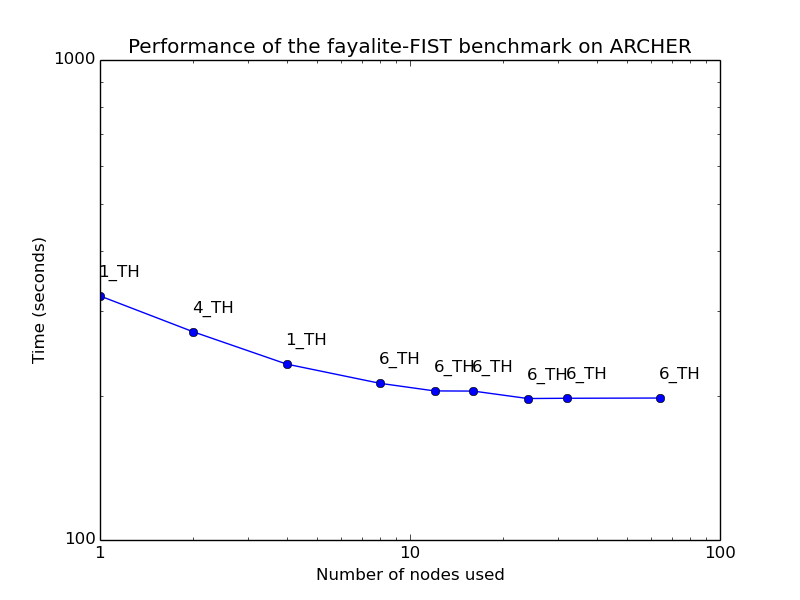
Fayalite-FIST - classical MD
CP2K includes classical force-field module FIST. While this is reasonably well optimised, it is not intended to compete with dedicated classical MD codes such as GROMACS, LAMMPS, but rather to allow for native QM/MM calculations.
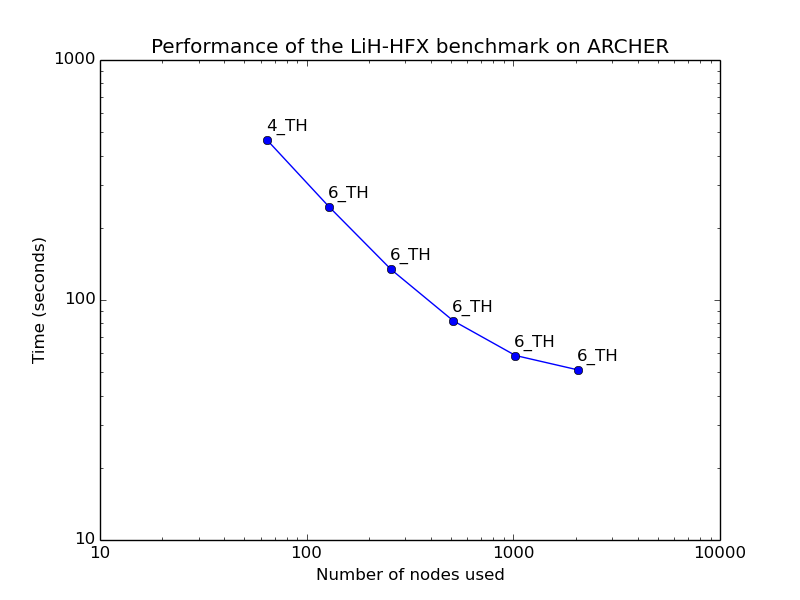
LiH-HFX - hybrid functionals
CP2K supports hybrid density functionals (B3LYP, PBE0, ...). This calculation uses the default hybrid functional implementation, which is 100s of times more expensive than a local density functional. It is also possible to use the ADMM method, which brings the cost down around two orders of magnitude. The Hartree-Fock code used for hybrid functional calculations benefits for mixed-mode MPI/OpenMP in order to allow more memory per process to store integrals - 4 or 6 threads per process is usually best.
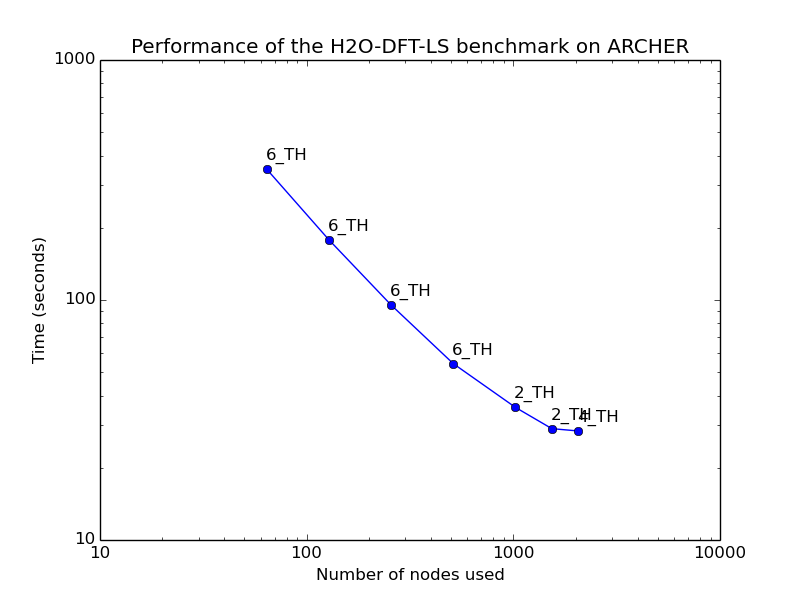
H2O-DFT-LS - linear scaling DFT
Standard DFT calculations using Quickstep scale formally as O(N^3), although the construction of the Hamiltonian is linear scaling. A fully linear scaling implementation based on density matrix iteration allows system sizes up to millions of atoms, and scales excellently in parallel. LS-DFT is typically faster than standard DFT for systems of over 5000 atoms. Excellent scaling is obtained up to a few atoms per MPI process - and using multiple OpenMP threads per process gives best performance.
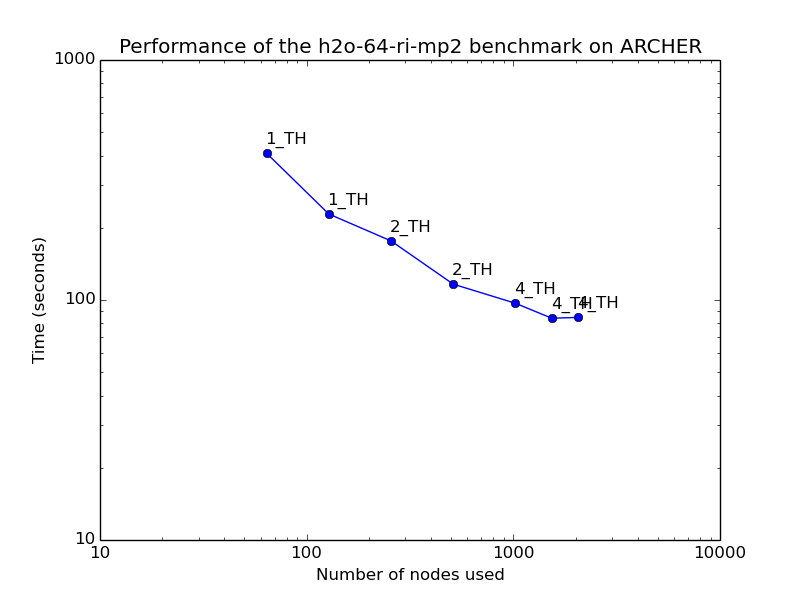
H2O-64-RI-MP2 - MP2 perturbation theory
CP2K contains low scaling implementations of the MP2 and RPA approximations for electron correlation. These are around 100 times the computational cost of a local DFT calculation, and give reasonable parallel scaling up to a few atoms per ARCHER node. Moderate numbers of OpenMP threads per MPI process may improve performance, especially for very large runs.